Measures of Central Tendency
Introduction:
A measure of central tendency is a single
value that attempts to describe a set of data by identifying the middle or the
center position within that set of statistics. It is
occasionally called an average, center of the distribution, measures of central location and also classed as summary statistics. The mean
often called the average is most likely the measure of central tendency that
you are most familiar with, but there are others, such as the median and the
mode. The mean, median and mode are all valid measures of central tendency, but
under different conditions, some measures of central tendency become more
appropriate to use than others.
Mean:
Mean is what most people commonly refer to
as an average. It can be used with both discrete and continuous data,
although its use is most often with continuous data. The mean is equal to the sum up a given
set of numbers and then divide this sum by the total number in the set. Mean is
also referred to more correctly as arithmetic mean. In statistics there are two
kinds of means: population mean and sample mean. A population mean is the true
mean of the entire population of the data set while a sample mean is the mean
of a small sample of the population.  So, if we have n values in a
data set and they have values x1, x2, ..., xn,
the sample mean,
and it is pronounce by X bar:
So, if we have n values in a
data set and they have values x1, x2, ..., xn,
the sample mean,
and it is pronounce by X bar:
This formula
is usually written in a slightly different manner using the Greek capitol
letter,∑,
pronounced "sigma", which means "sum":
Population mean is represented by the
Greek letter μ pronounced mu. The total number of elements in a
population is represented by N:
The sample mean is commonly used to
estimate the population mean when the population mean is unknown. This is
because they have the same expected value.
Median:
The
median is defined as the number in the middle of a given set of numbers
arranged in order of increasing magnitude. When given a set of numbers, the
median is the number positioned in the exact middle of the list when you
arrange the numbers from the lowest to the highest. The median is important
because it describes the behaviour of the entire set of numbers. For example, we
have a set of number
15, 16, 15, 7,
21, 18, 19, 20, 11
From the definition of median, first step is to rearrange the given set of
numbers in order of increasing magnitude:
7, 11, 15, 15,
16, 18, 19, 20, 21
Then we
inspect the set to find that number which lies in the exact middle.
Median = 16
So, if we look at the another example that often occurs when solving for the median.:
65
|
55
|
89
|
56
|
35
|
14
|
56
|
55
|
87
|
45
|
We again rearrange that data into order of magnitude
(smallest first):
14
|
35
|
45
|
55
|
55
|
56
|
56
|
65
|
87
|
89
|
92
|
Only now we have to take the 5th and 6th score in our
data set and average them to get a median of 55.5.
Mode:
The mode is defined as the element that appears most
frequently in a given set of elements. On a histogram it represents the highest bar in
a bar chart or histogram. Therefore, sometimes consider the mode as being the
most popular option.
For example, in the 3, 3, 6, 9, 16, 16, 16, 27, 27, 37, 48 are the set of numbers, here 16 is the mode
since it appears more times than any other number in the set.
A set of numbers can have more than one mode this is known as bimodal,
if there are multiple numbers that occur with equal frequency, and more times
than the others in the set.
3, 3, 3,
9, 16, 16,
16, 27, 37, 48
In this example, both the number 3 and the number 16 are modes.
If no number in
a set of numbers occurs more than once, that set has no mode:
3, 6, 9, 16, 27, 37, 48
in this list there is no mode.








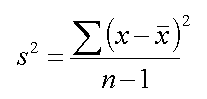


.bmp)
.bmp)



.bmp)
{kind=link}
{kind=link}